2021 0009 0012
My raison d’être for creating the wall-mounted dashboard discussed in previous posts was to help with timing my transit connections when leaving my NYC apartment. After living on my block for a few months, I had worked out the perfect time to step out the door to make a subway, bus, or ferry connection, but quickly grew tired of having to pull out my phone to verify the transit time. I basically wanted an equivalent of the MTA transit time boards found in most subway stations, customized with my local stations.
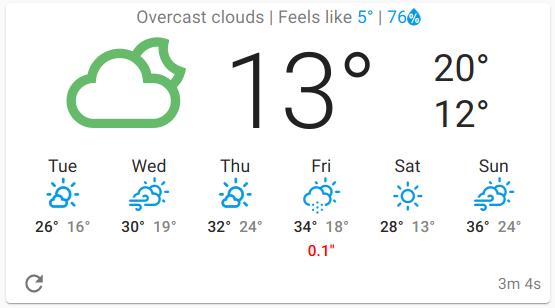
Jumping straight to a sample of the end result, I wanted a dashboard like this:
Building this view, however, is less simple than it sounds. A big part of the complexity is in finding and consuming a source for the transit departure times. Unlike the weather card, there isn’t a single, free, purpose-built API to serve such dashboards. To deal with transit, we have to solve two main challenges:
-
Finding a source for the transit data we need to display on the dashboard.
-
Consuming transit data from the above source, stitching it together to populate the view.
For narrative reasons, we’ll take these points in reverse order before delving into the implementation.
Consuming Transit Data
The most common way to address (2) is by consuming a source that adheres to the GTFS (General Transit Feed Specification), the defacto standard for transit data that is published by many transit agencies. It has complementary static and realtime flavors, and we need both sources to get the most accurate data for our dashboard.
To better understand the complexity of GTFS, this is a (very rough) entity relationship diagram:

Note that there are other similar ERDs that are likely better-researched but didn’t fit quite as nealy into this post so I took a stab at creating this diagram myself. There are a few caveats in the image above: There are a lot of conditional relationships in GTFS that are not captured in this image; similarly, there are also a number of nested entities in the realtime spec that are glossed over in this diagram for simplicity.
GTFS is quite normalized so there isn’t an obvious self-contained single entity we can read that will let us drive everything in our dashboard. Combing through the GTFS entities, there is a sizable number that are not relevant to displaying transit times at a chosen station. Removing entities related to fare calculation, pathing, language translation, station layout, and so forth, the resulting trimmed-down ERD looks like:

This subset of the GTFS is a bit more manageable for demonstrating
what we need to consume for our dashboard. The particular relevant
subset might be different for other agencies (e.g., some agencies
might rely more on frequency-based service or have calendar-based
service changes) but this is all I needed based on the MTA GTFS.
Exploring this subset in more detail, the agency entity isn’t
strictly necessary except in cases where the feed represents multiple
agencies. To populate the dashboard, we will identify one or more
stops, use these stops to filter the stop times list which allows
us to compute the arrival times at a given stop. This would be
sufficient for our dashboard if there’s a single transit line going in
a single direction at a given stop. However, if there’s multiple
routes or directions of travel at a particular stop then we need to
split the stop times into groups by direction and route to
differentiate them. To accomplish this, we additionally look up the
trip for each stop time which gives us information about the trip
direction, and then walk through trips to routes which allows us
bucket the stop times into groups by route.
So far, we’ve only touched the entities in the static GTFS, which is
sufficient if the agency consistency runs on time (🤣). To bring the
prescheduled stop times into alignment with reality, we read the
trip updates Realtime source and (hand-waving a lot here) update the
stop times with these realtime updates at a reasonable interval.
At a high-level, this is our roadmap for reading the subset of the GTFS that we need for this dashboard.
Serving Transit Data
Stepping backwards to address point (1) above, we need to talk about
how we physically convey GTFS data into our web application. The
static portion of the GTFS is a zip file containing .txt files
(effectively CSV formatted)–not impossible to download directly from
the transit agency into a web application with the right
decompression and parsing libraries, but hardly
idiomatic. The GTFS Realtime format is even more challenging as it is
serialized as a Protocol Buffer. It might be theoretically
possible to consume the realtime ProtoBuf stream by providing the
.proto file to the browser and using a ProtoBuf javascript
decoder; in practice, the real-time updates from the MTA are megabytes-to-gigabytes and are updated frequently enough
that I had concerns as to whether a cheap, wall-mounted tablet would
be able to handle parsing the feeds in-browser at a reasonable
frequency.
Thankfully, there are multiple server-side options available which vary in quality, completeness, and implementation language. Choosing a minimal GTFS server could absolutely work for this use case, but I ultimately ended up gravitating towards the Open Trip Planner (OTP) project which specializes in route planning (including surface street connections using OpenStreetMap). Not only does OTP consume GTFS (both static and realtime) for use in its route planning, it caches the serialized results for faster reloading, has a fetching mechanism to pull the feeds in at a regular cadence, and–most importantly for our intended application–has an Index API which provides a REST interface to query GTFS entities. Even better, it is becoming increasingly common for transit agencies themselves to host an OTP instance for their route planning or transit time needs–if such an instance is public-facing, using it saves a lot of work configuring and hosting our own OTP instance.
The discussion from the previous section roughly translates to the following Clojure pseudocode to walk through the GTFS entities and collect a useful payload:
(defn stop-times
[stop-id]
(->> stop-id
fetch-stop
fetch-stop-times
(map (fn [stop-time]
(let [trip (fetch-trip (:trip-id stop-time))
route (fetch-route (:route-id trip))]
(assoc stop-time
:route route
:direction (:direction trip)))))))
Following this, we can concat all the stop-times from all the
stop-ids together and do a (group-by #(select-keys % [:direction
:route])) to bundle them into the rows displayed in the dashboard.
From the Index API, the following endpoints look promising to meet these needs:
| stop | /index/stops/{stop-id} |
| stop times | /index/stops/{stop-id}/stoptimes |
| trip | /index/trips/{trip-id} |
| route | /index/routes/{route-id} |
As it turns out, the Index API is able to flatten the trip into the
stop entity (/index/stops/{stop-id}) for us in the scenario where
the stop services a single line + direction. This does not initially
sound like a very useful optimization for more complex transit systems
that routinely have multiple routes traveling multiple directions that
stop at the same station. However, in the case of the MTA’s GTFS, the
agency choose to model stations hierarchically, where the main station
is the parent stop and different lines+directions are child stops
within the same overall station. The Index API also directly adds the
route-id to the individual stop times (i.e., it traverses the
stop-time -> trip entities for us). Thus by choosing these “child”
stops that represent a single line + direction, we can save having to
make the additional trip call to get the direction + route ID. Under
this optimization assumption we get an even trimmer effective ERD:

Depending on your particular agency, this optimization may not be applicable or might be overkill if you’re hosting your own OTP and don’t have any concerns about the number of API queries. If self-hosting, this might be a good candidate for the BFF pattern, but the rest of this post assumes a preexisting OTP instance without any extra server-side components on top of it.
Implementation
Now that we’ve settled on the physical API to use and know the relationships among the entities we need for our dashboard, all we have left is to code and style it. Rather than go line-by-line as in previous installments, I’ll only be going over the highlights of the source code in this section.
As with other external APIs we need to hit, we use
re-frame-http-fx for defining the “effect handlers” that made the
side-effecting REST calls. An example where we fetch the stop-times
(assumes that the stop has already been fetched and is passed as
input):
(re-frame/reg-event-fx
::fetch-stop-times
(fn [_ [_ {:keys [stop-id] :as stop}]]
{:http-xhrio
(merge
otp-request
{:uri (str config/otp-uri
"/routers/default/index/stops/"
stop-id
"/stoptimes")
:on-success [::persist-stop-times [:transit :stop-times stop]]
:on-failure [::events/http-fail [:transit :stop-times stop]]})}))
The notable part of this effect handler is the ::persist-stop-times
event which is dispatched when the effect handler is successful. The
::persist-stop-times event is, itself an effect handler that
persists the stop-times API payload into the re-frame.db/app-db
while also fanning out (:dispatch-n) to trigger ::fetch-route
events for all the new route-ids that it finds:
(re-frame/reg-event-fx
::persist-stop-times
(fn [{:keys [db]} [_ key-path stop-times]]
(let [existing-route-ids (-> db :transit :routes keys set)
new-route-ids (->> stop-times :route :id set)
;; diff what is in the DB with the newly-seen routes so we
;; only fetch them once
route-ids (->> (difference new-route-ids
existing-route-ids)
(remove nil?))
stop-id (-> key-path last :stop-id)]
{:db (assoc-in db key-path stop-times)
;; fire requests for the routes listed in the payload
:dispatch-n (map (fn [route-id]
[::fetch-route route-id])
route-ids)})))
The route-fetching events are fired after fetching the stop times
because the routes that serve a particular stop might change at any
given point so we don’t necessarily know all the routes ahead of time.
And it would be better not to have to preemptively fetch every route
in the system, particularly for larger agencies like the MTA. We also
want to avoid re-fetching the same routes over and over again, so
route-ids that are already present in the app-db are not fetched
again to minimize API queries, effectively treating the app-db as a
cache.
How the stop and route entities are persisted is less interesting
so I’m omitting examples of them here. Just like the weather
API prior, we now need only to poll the
transit
API
at regular intervals to make sure our app-db always has fresh
information ready for display.
Like other re-frame applications, now that we have our events defined
we need to create subscriptions on the resulting app-db changes to
turn these raw OTP Index API payloads into a processed form ready to
be used by our view. Our “Level 1” subscriptions are fairly simple:
(re-frame/reg-sub
::stop-times-raw
(fn [db _]
(-> db :transit :stop-times)))
;;; Repeat for stops and routes...
which fetches the raw API payload for the stop-times, which looks
something like this:
[{:route {:id "MTASBWY:1"}
:times
[{:departureDelay 0
:stopName "South Ferry"
:scheduledDeparture 89130
:stopId "MTASBWY:142N"
:directionId "0"
:serviceDay 1592539200
:tripId "MTASBWY:5953"
:realtimeDeparture 89130
:stopHeadsign "Uptown & The Bronx"
:tripHeadsign "Van Cortlandt Park - 242 St"}]
...}
...]
Note the realtimeDeparture field which is updated by OTP with the
GTFS Realtime source. This payload goes through a cleanup
subscription that grabs specific keys from the payload, places them
into a flattened data structure, and converts the fixed departure
timestamp into a “minutes from now” format that we’ll want in our
view:
(re-frame/reg-sub
::stop-times
:<- [::stop-times-raw]
:<- [::clock/clock]
(fn [[stop-times clock] _]
(let [now (time-coerce/from-date clock)]
(->> stop-times
vals
(apply concat)
(mapcat
(fn [{:keys [times route]}]
(->> times
(map #(assoc % :route route))
(map
(fn [{time :realtimeDeparture
day :serviceDay
stop-id :stopId
{route-id :id} :route
direction-id :directionId}]
{:minutes (-> time (+ day) (* 1e3)
time-coerce/from-long
(->> (safe-interval now))
time/in-seconds
(/ 60)
js/Math.ceil)
:stop-id stop-id
:route-id route-id
:direction-id direction-id})))))))))
This subscription code is detailed and has some assorted helpers
(safe-interval, the cljs-time namespaces) that are significant but
not worth a tangent right now. As before, I’m also omitting similar
cleanup subscriptions for the stop and route payloads.
Finally, we join all three of stops, stop-times, and routes
together with a 3rd-level subscription:
(re-frame/reg-sub
::stop-times-processed
:<- [::stop-times]
:<- [::routes]
:<- [::stops]
(fn [[stop-times routes stops] _]
(->> stop-times
(filter (-> (every-pred nat-int? (partial > 60))
(comp :minutes)))
(map (fn [{:keys [stop-id route-id] :as stop-time}]
(-> stop-time
(assoc :stop (get stops stop-id))
(assoc :route (get routes route-id)))))
;; Make this an inner join
(filter (every-pred :stop :route))
;; Group by stop only
(group-by #(select-keys % [:stop]))
;; Add route to key after grouping to keep routes together
(map (fn [[k v]]
[(assoc k :route (roll-up-route v))
v]))
(into {})
(map-vals #(->> %
(filter
(fn [{:keys [direction-id]
{stop-direction-id :direction-id} :stop}]
(or
(= direction-id stop-direction-id)
(nil? stop-direction-id))))
(sort-by :minutes)
(take 4)))
(sort-by (juxt (comp :sort-override :stop first)
(comp :sort-order :route first)
(comp :stop-id :stop first))))))
This is a lot to unpack, especially compared with the pseudocode above (which probably means this code needs some refactoring into more subscriptions); out of laziness, I’ll just summarize the highlights:
- Keep only
stop-timesthat are less than 60 minutes out - The
stopandrouteare attached to thestop-timewith an inner join - Group all
stop-timesby the differentstopsthey represent - Do a “roll up” of all the routes attached to the stop times inside
of each group with the
roll-up-routefunction, which lets us show a stop, say Lex/63rd, as a single row labeled “F/Q” rather than having separate rows for the F and Q lines. This is typically more useful for express lines or other situations where you care only about the latest departure but don’t care about the particular line. - Filter out mislabeled stop times going the wrong direction at a stop
- Sort the stop times in each group in ascending order
- Take the first four stop-times in each group to show in the view
- Sort the groups themselves
We now have a stable, easy-to-consume set of groups corresponding to all the stops we care about, each with up to four upcoming departure times in minutes.
This payload is subsequently rendered in the view. Recall that we want a series of rows in our view that look like:

where the arrow specifies the direction of travel, the round symbol specifies the particular route name, and the stop times fan out to the right. This is rendered with:
(defn transit []
[:> Card {:height "48vh"}
[:> CardContent
[:> Grid {:container true :spacing 1 :alignItems "center"}
(map
(fn [[{{:keys [color text-color short-name route-id]} :route
{:keys [direction-id stop-id]} :stop}
stop-times]]
;; Since this element is being dynamically generated, must
;; specify key so React can do its reconcilliation
[:<> {:key (str stop-id "-" route-id)}
;; Arrow pointing up or down corresponding to the direction
[:> Grid {:item true :xs 1}
[:> Typography {:variant "h4" :color "textSecondary"}
(get direction-id->arrow direction-id "")]]
;; Line symbol that takes its color directly from the
;; transit agency's route metadata
[:> Grid {:item true :xs 2}
[:> Avatar {:style {:background-color (str "#" color)
:color (str "#" text-color)}}
short-name]]
;; Render the stop
(->> (concat stop-times (repeat nil))
(map-indexed
(fn [idx {:keys [minutes] :as stop-time}]
[:<> {:key idx}
[:> Grid {:item true :xs 2}
(when stop-time
[:> Typography
[:span
(if (> minutes 0)
[:<> minutes [:span "m "]]
"Now ")]])]]))
(take 4))
[:> Grid {:item true :xs 1}]])
@(re-frame/subscribe [::transit/stop-times-processed]))]]])
This is another beast of a function (and I omitted some styling just
to trim it down this small), but broken down is not too complicated:
The outer map generates a row where each row consists of the up/down
arrow and a circular Avatar symbol with the line short-name to
display the route. The inner map-indexed generates exactly 4 stop
times (or empty Grid items to pad out the grid).
Conclusion
Since this the final post in the series, I would be remiss not to include some photos of the finished product:
 |
 |
Differing slightly from the first installment, I’ve since replaced the stock chart in the lower right with a webcam view from NYC DOT but kept the appearance otherwise unchanged.
The dashboard is displayed on an inexpensive, previous-generation Amazon Fire 8 using the WallPanel app (having switched away from Fully Kiosk for this open-source option) to keep the ClojureScript SPA running continually. To physically affix the tablet to the wall, I purchased a tablet wall mount which adheres using Command Strips. A wall-colored Micro USB cable to keep the tablet charged completes the installation.
So far, this setup has been working well. There are some minor annoyances with the hardware: This particular Fire tablet does not make ambient light adjustments to the screen brightness so it lightens my living room considerably at night. Given that this tablet is a full order of magnitude cheaper than the premium tablet options, it has been more than sufficient for this purpose and I won’t be overly upset by battery or screen burn-in issues long-term.
| Part 1 | Part 2 | Part 3 |