2012 0007 0008
Like anyone for whom graduation is becoming more immanent, I’ve been taking a look at the latest trends in the typical technology interview process. While many of the Fizz Buzzes being thrown around aren’t exactly exciting highlights of problem solving… well, you can always just beat them to death.
The Run Length Encoding algorithm is a nice, compact, and
slightly real-world interview problem that has been making the rounds
for years now. The basic idea being that “runs” of data,
e.g. aaaabbbbbbb, are compressed into tuples, e.g. 4a7b, which may
be a smaller representation if there is a large amount of adjacent
repeated information. While real-world use cases for such a naïve
compression scheme aren’t abundant, the algorithm is straightforward
and can be implemented in a dozen lines or so in most languages.
If you’ve got regexes or similar libraries at your disposal, you can
manage even fewer lines. In Haskell’s case, one:
rleMap l = map (\e -> (head e, length e)) (group l)which converts a string (or any arbitrary list of items) into a list of tuples, each of which has the character and its count. The function has type
rleMap :: (Eq a) => [a] -> [(a, Int)]Simple and easy. But where’s the fun in calling it quits now?
Let’s MapReduce our RLE algorithm to make it easier to parallelize
and potentially Hadoop-friendly. We’ve already got our map
function, so lets create a reduce:
rleReduce :: [(Char,Int)] -> [(Char,Int)] -> [(Char,Int)]
rleReduce [] [] = []
rleReduce a [] = a
rleReduce [] b = b
rleReduce a b
| (fst $ last a ) == (fst $ head b) =
init a ++ [(fst(last(a)),snd(last(a)) + snd(head(b)))] ++ tail b
| otherwise = a ++ bThis is a less common component of RLE implementations (I haven’t
spotted this particular bit of code anywhere else, so there’s likely
room for improvement), but no less straightforward: simply join two
RLE‘d lists together if their tail and head are not the same
character; if they are, merge the head and tail tuple (updating the
count) and combine the rest of the list as normal.
Now, it’s simply a matter of splitting the RLE target into pieces,
maping over pieces, and reducing them back into a cohesive
RLE-encoded document:
splitRLE n s = foldl rleReduce [] $ map rleMap $ chunkn n s(chunkn is a simple hand-rolled routine that splits a string into
n similar-sized pieces) As expected, splitting the list apart and
recombining is needless overhead without parallelization:
# No splitting (rleMap s)
> ghc -O2 prle --make
> /usr/bin/time -f '%E' ./prle large.txt 1>/dev/null
0:02.68
# Nonparallel splitting (foldl rleReduce [] $ map rleMap $ chunkn n s)
> ghc -O2 prle --make
> /usr/bin/time -f '%E' ./prle large.txt 1>/dev/null
0:06.51
If we parallelize it using a simple parMap,
parallelRLE n s = foldl rleReduce [] $ (parMap rdeepseq) rleMap $ chunkn n swe might expect some improvement:
# parallelRLE n s = foldl rleReduce [] $ (parMap rdeepseq) rleMap $ chunkn n s
> ghc -O2 prle --make -threaded -rtsopts
# Parallel map 1 core
> /usr/bin/time -f '%E' ./prle large.txt +RTS -N1 1>/dev/null
0:06.31
# Parallel map 2 cores
> /usr/bin/time -f '%E' ./prle large.txt +RTS -N2 1>/dev/null
0:08.50
# Parallel map 4 cores
/usr/bin/time -f '%E' ./prle large.txt +RTS -N4 1>/dev/null
0:11.00
Unfortunately, the bookkeeping and garbage collection overwhelm the problem very quickly, never achieving better performance.
I’m running the above on a randomly-generated 12MB text file, and no
amount of coaxing could make the parallelized version do any better.
While we could have written our RLE algorithm in plain C without
much more trouble and not have encountered such performance obstacles,
one does not simply parallelize C by swapping in a parMap
either (see also: this). Thus, we deep-dive into some Haskell
optimization to get a performant version.
There is one particularly painful bottleneck: Haskell list monads
are not ideal for handling bulk data of the sort we need because
Haskell’s String type is represented as a [Char]. Since there’s
no reason to use a boxed linked list just to scan over characters, we
instead turn to Data.ByteString for reading the input, and to
Data.Sequence to handle the RLE-encoded tuples. Data.Sequence
specifically removes the large penalty when concatenating the lists
together in the reduce step, as adding to either end of a Seq is a
constant time operation. This is in contrast to [], where only
adding an element to a list head is constant time. Importing these
import Data.ByteString.Lazy.Char8 as BL
(ByteString
,length
, take
, null
, splitAt
, group
, head
, pack
, readFile)
import Data.Sequence as Slets us rewrite our map
rleMap :: BL.ByteString -> Seq (Char,Int)
rleMap l = fromList $ P.zip (map BL.head c) (map (fromIntegral . BL.length) c)
where
c = BL.group $ land reduce
rleReduce :: Seq (Char,Int) -> Seq (Char,Int) -> Seq (Char,Int)
rleReduce a b = rleReduce' (viewr a) (viewl b)
where
rleReduce' EmptyR EmptyL = S.empty
rleReduce' EmptyR _ = b
rleReduce' _ EmptyL = a
rleReduce' (rs :> r) (l :< ls)
| (fst r) == (fst l) =
(rs |> (fst(r),snd(r) + snd(l))) >< ls
| otherwise = a >< bOptionally, Data.Sequence can be expressed with ViewPatterns.
Rewriting with these in mind allows the new reduce to resemble the
old one fairly closely:
{-# LANGUAGE ViewPatterns #-}
rleReduce (viewr -> EmptyR) (viewl -> EmptyL) = S.empty
rleReduce (viewr -> EmptyR) b = b
rleReduce a (viewl -> EmptyL) = a
rleReduce a@(viewr -> (rs :> r)) b@(viewl -> (l :< ls))
| (fst r) == (fst l) =
(rs |> (fst(r),snd(r) + snd(l))) >< ls
| otherwise = a >< bNow we finally define a new parallelRLE
parallelRLE :: Int -> BL.ByteString -> Seq (Char, Int)
parallelRLE n s = foldl rleReduce empty $ (parMap rseq) rleMap $ chunkn n sand wrap it all up in a IO monad
main :: IO()
main = do
[fileName] <- getArgs
s <- (BL.readFile fileName)
print (parallelRLE (numCapabilities) s)With an improved algorithm and IO wrapper, it’s time for a more
complete benchmark:
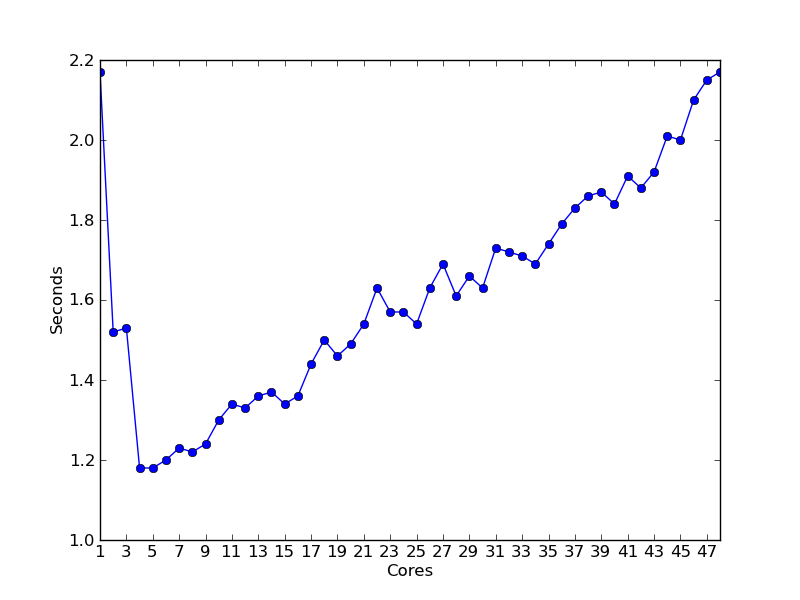
This was run on a 0.5GB file, as the smaller 12MB file used above
runs so fast that is essentially instant. Between 2 and 5 processors,
we get a nicely ramped speedup. After 5 processors, the bookkeeping
overhead rears its ugly head again reversing the trend, and around 48
processors (my system maximum), the parallelization ends up running as
slowly as the unparallelized version. This is certainly not the end
of possible optimizations, but we have to stop sometime.
While I’m no Haskell expert, parallelization which costs no more
than swapping in a parMap and paying homage to the Big O gods is a
very compelling reason to hammer out any other toy interview questions
with Haskell in the future.
Get the code here. Feedback welcome.