Years ago, before I got my hands on a real compiler, I satisfied my
coding compulsion by modding Jedi Knight: Dark Forces II (which,
yes, has the subtitle backwards from normal). As detailed
elsewhere, Jedi Knight (abbreviated JK) is one of the earlier
examples of a game that used a simple scripting language to handle
interaction with the game engine. COG script, as it was called was, in
hindsight, designed as much to be easy to compile as it was to write.
Of course, the attractive thing to any 13-year-old who desperately
wants to code in a “real” language was COG’s (superficial) similarity
to C.
The structure of a COG script is straightforward: it starts with a
symbols section, where all variables are declared, followed
by a code section broken into various messages (denoted by
goto-like labels, which must be declared as variables in the symbol
section to be valid) that represent events that could be triggered
in-game. Aside from the usual expressions and flow control, there are
library functions that form an elementary API for the game engine
itself. Variables are typed, and have one of two scopes. The “local”
variables are bound within the scope of the script itself. All
non-local variables must be bound to external entities in the game
environment–think of them as free parameters that must be specified
outside the script. Variable types include a few atomic types (e.g.,
int, flex) and some game-specific entities (e.g., things, surfaces),
and event types (e.g., messages). Have a look:
symbols
surface downsect
message activated
thing ghosttel1
thing ghosttel2
thing player local
surface upsuf1
end
code
activated:
if (GetSenderRef() == upsuf1)
{
player = GetLocalPlayerThing();
TeleportThing(player, ghosttel1);
return;
}
if (GetSenderRef() == downsect)
{
player = GetLocalPlayerThing();
TeleportThing(player, ghosttel2);
return;
}
return;
end
The above code works as you would expect–it simulates a “ladder” by
simply teleporting the player to the top of the ladder if they
“activate” (by pressing the spacebar while standing near) a surface at
the bottom, or teleports them back down if they activate the ladder
surface at the top.
With no reference whatsoever–beyond the COGs included with the game
itself–it took me a while to get used to writing COG. But given that
it had one of the more fun compilers around (though billed as a
scripting language, COG was actually compiled to a stack-based
language at load-time), I had little trouble finding motivation to toy
with it.
Aside from COG, JK had a variety of other specialized file types that
could be (relatively) easily created or modified: .3do for 3D
models, .mat and .bm for images (bitmaps, essentially), .jk for
level meta information, .pup (puppet) files that link keyframed
animations to specific pose states for a character, .key files which
are the keyframed animations for the characters, .snd files that
link sound to a character, .ai files that expose variables for how
the characters react (simple artificial intelligence), .gob files
which are essentially .zip files for storing all the various resources
in a level, and many many more file types I’m probably forgetting.
But it was always the COGs that were most interesting to me, despite the fact that I wrote some ugly and embarrassing code in it. Really embarrassing.
And I won’t even get started on my very unrefined sense of aesthetic
design in the level I ended up building. Yes, I built an entire level,
mainly to facilitate being able to write fun little scripts in
COG. Which is not nearly as involved as it sounds thanks to JED,
a community-supported level editor. I built a very basic plotline with
a number of cutscenes (9, I claim in the readme); a weapon mod
that added a phaser to your arsenal (you know, the Star Trek sort–I
never claimed any of this made sense except to my 13-year-old self);
two new types of enemies, as I never thought the original lineup was
difficult enough; a few secret areas, including one with a rather
famous character; a zoo (again, never said anything about making
sense); a few RPG-style quests; and committed some very horrible
texture misuse, a fact that the contemporary reviews will back
up.
I did learn some rather important software engineering lessons along
the way. I recently ran across my issue-tracking system: a notepad
with 50+ pages of bugs and fixes that I did on the level for the year
or so it was in development. Everything from enemies falling through
floors, cutscenes being mistimed, and impossible-to-win scenarios,
were among the issues I recorded. I simply couldn’t keep track of the
number of issues I would notice on every playthrough without writing
them down.
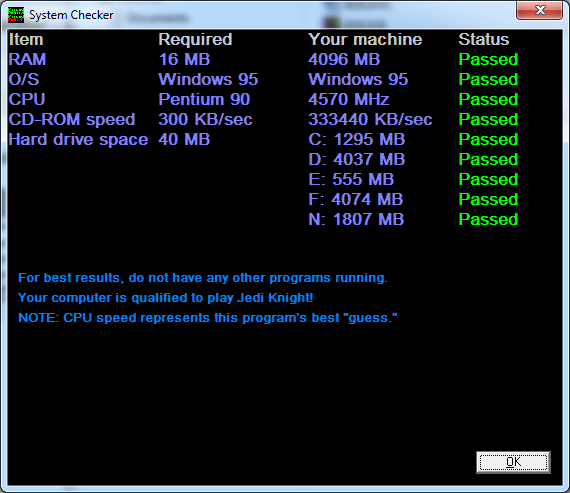
On my nostalgic adventure, I decided to actually get Jedi Knight up
and running again. I think my PC was perfectly adequate to run the
game, according to its own system requirements analyzer:
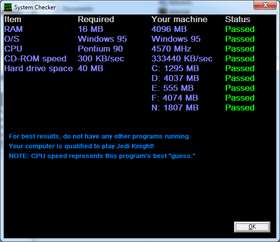
Though it was incorrect about the "Windows 95" part.
Thankfully, a kind soul rewrote the 16-bit installer (here) so,
if you happen to have the Jedi Knight CDs on hand, you can actually
install it on a 64-bit Windows (virtual) machine.

Ah, nostalgia.
Getting any new level up and running is typically as simple as placing the .gob file in the EPISODES folder. So, of course, I loaded up my old creation. I definitely had a lot of fun as a kid.

Completely forgot about the in-game menu system (so you could bypass
the rather dry "Story" cutscene I included, among other things).
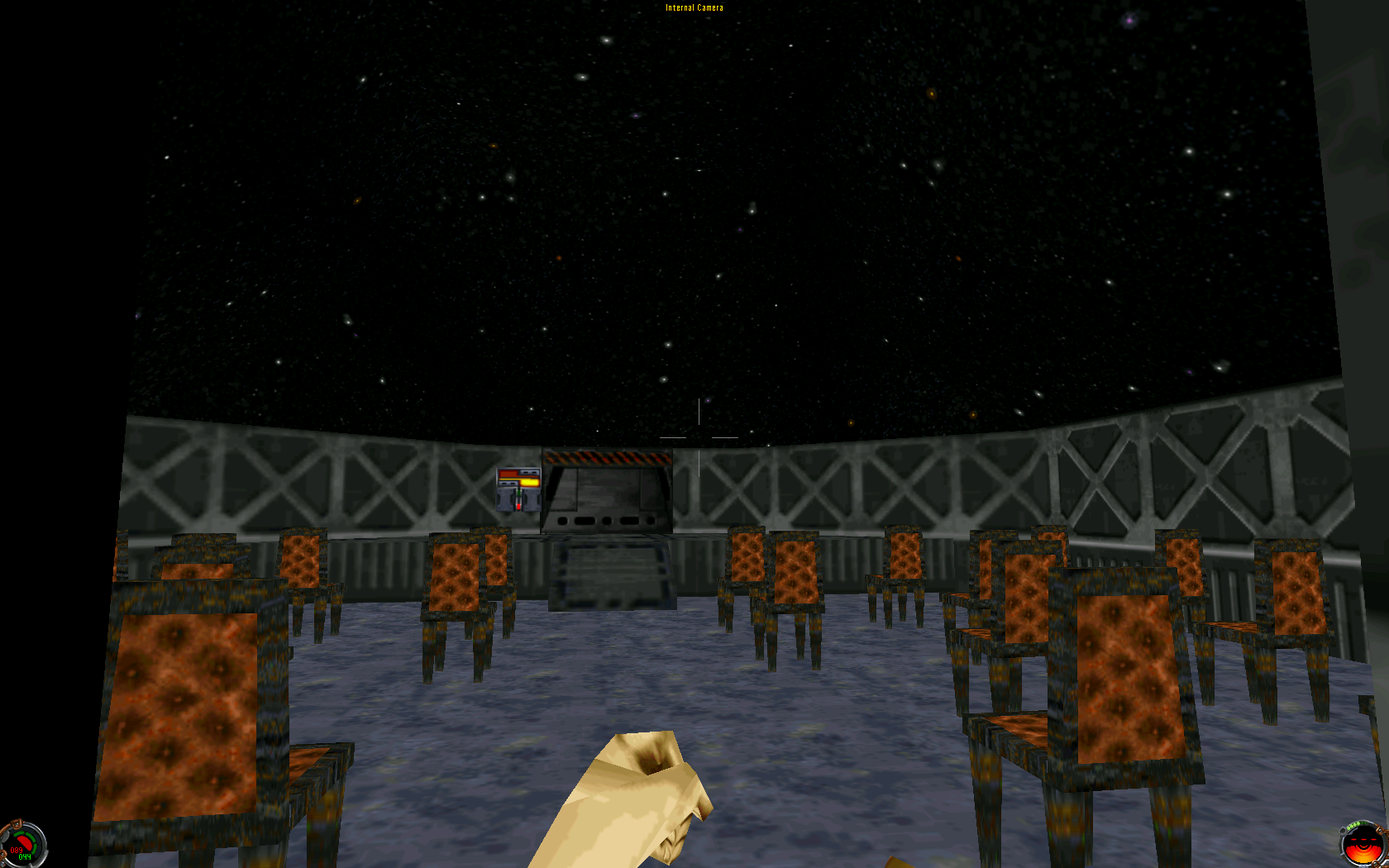
A planetarium. On a star destroyer, for some reason.
The aforementioned zoo.
Oddly, I also included a kitchen. Complete with an oven you have to
crawl into to complete a mission objective.

The obligatory "dress up as the enemy to get through a checkpoint"
plot point.

A sewer at the bottom of a detention center. Even star destroyers have
to take care of their waste somehow.

Grand Admiral Thrawn himself, wielding a phaser. And fairly deadly at
that--I died a dozen times or so before beating him.

Barney makes an appearance. And yes, you can obliterate him.
While my handiwork hasn’t aged well (and neither has JK, for that
matter), I’ve placed the entire monstrosity on my github for
posterity’s sake: https://github.com/malloc47/return-of-thrawn.
Reflecting back, COG certainly wasn’t the most stretching or important
language I learned (by a long-shot), nor was building my level the
most disciplined software engineering project I’ve undertaken, but it
was one thing: it was enthralling enough to keep a kid hooked on
coding and building cool things. Before the era of web apps and mobile
apps, or code academies and khan academies, or Scratch and Alice, I
feel rather lucky to have stumbled on something that was
simultaneously fun and empowering. JK wasn’t just a game. It was an
ecosystem. It was an IDE. And it was fun.